
Langfuse Teardown
Dealing with Errors in a Prompt Manager

Today I am reviewing Langfuse, a prompt management tool, to see how well it handles errors that crop up during the course of building an AI based application.
This is the Langfuse trace panel. Rather showing traces on the dashboard for each individual prompt they went with a universal tracing panel for all prompts together. If there is an error with you prompts, this is where you will be investigating. C

Clicking on an individual trace then opens up a detailed view of that individual prompt call that looks like this:

I understand that it’s just showing me the inputs and the outputs for a single prompt call, but I feel intimidated. This level of overwhelm seems a bit unreasonable given that I just want to know if the call was successful or not.
Setting things up to get to this stage was also confusing. The original set up to retrieve a prompt from Langfuse looked like this:
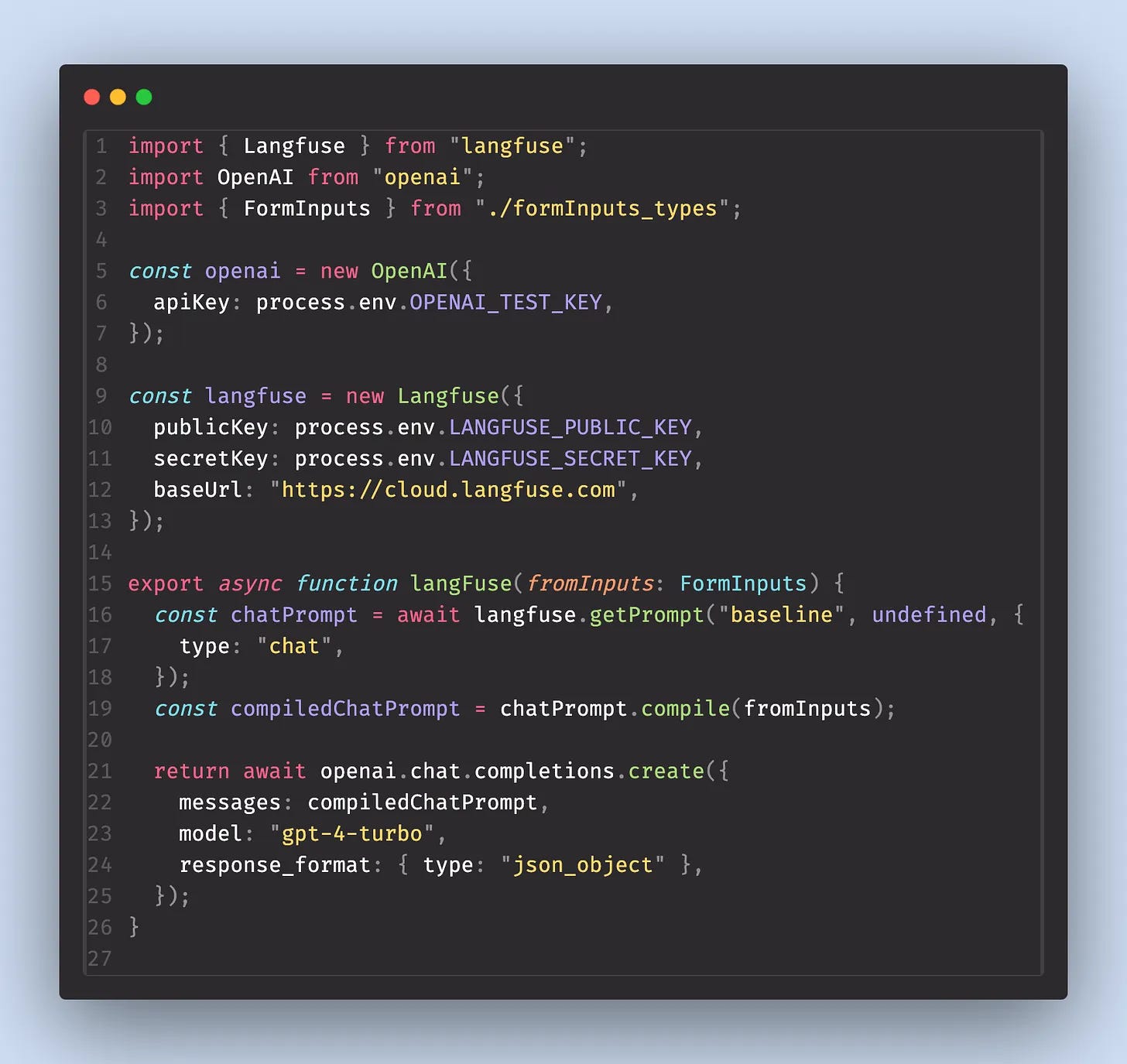
Compare this to the screenshot below with everything I had to change to get calls to show up in the tracing panel. That’s a lot of extra code, given that I am tracing prompt that are stored on Langfuse.

Anyways, now that everything is setup , let see how well the system helps me detect errors when something goes wrong.
Changing the shape of the payload ❌
I switched the shape of the payload to a prompt from an object where each key corresponded to a form field in my simple app to an array with the same values.

To be clear, I’m not expecting this to work. What I want to understand is how it handles these kind of catastrophic changes.
Prompt Manager - No Failure
The prompt ran normally. There was no indication of any errors. It returned a normal response. I could see the array passed in as inputs on the trace but the output had nothing to do with the inputs. ChatGPT just ran the prompt without inputs and made up a response.

Codebase - No Failure
There were no errors in the code base. This was expected prompt ran as normal and just returned a made up response, rather than creating content related to the information I was passing in.
Sending too much information 🙈
Next I tried adding an extra key value to the object I was passing into my prompt. So instead of sending a payload object with data from 5 form fields, I was sending an object with 6 bits of information.
Prompt Manager - The prompt worked as normal, this time it did return a response that was relevant to the inputs. But it just ignored the extra information. That said, I was able to see the extra information passed in though, but nothing to alert me to the fact that the prompt was receiving information that it was not using.

Codebase - Same, no errors or warnings, the redundant data was just ignored.
Not sending enough information 🤐
I added a new input variable to the prompt in the prompt manager to see if calling a prompt with insufficient data would throw any kind of warning.
Prompt Manager - The prompt worked as normal and just ignored the missing information. I could not find any way to mark a input variable as required. They all just seem to be optional by default.
Codebase - Same, I wrapped the call in a try catch block and there were no errors or warnings in my console.
No Rollbackability
I could see the different version of my prompts in the prompt manager but there was no way to roll back to a previous version now that I had made a mess of teh latest version with this extra input variable.

Returns Incomplete JSON ⚠️
Since Langfuse is a compiler, there is no way to adjust temperature and token settings in the prompt manager. I have to hardcode these kinds of changes into my api call in source code. This is unfortunate since the whole point of a prompt manager, from my perspective at least, is to give non-technical contribute a space to edit and optimize your prompts. Without access to configuration options like token count and temperature settings, they will have one arm tied behind their back.
regardless I hardcode the token limit to 40 and set teh repsonse format to JSON which would almost certainly force ChatGPT to return invalid JSON. I wanted to see if the Langfuse tracer would alert me to these kinds of detectable errors.
The response was incomplete JSON.

The tracer even gave the response a happy green background as if to say everything was fine, despite the finish reason being length in the response output.
On the developer end I do get a response object that has the headers. So I would be able to debug this and see that the reason it finished because of a length limitation ("finish_reason": "length")
However I would have liked to also see this in the prompt manager since this is clearly an avoidable and easily detectable error but I was not alerted to it in any way.
I felt out of my depth setting Langfuse up and using it to trace calls. I had hoped that all the extra chrome would have made it much easier to detect simple errors like the ones I went through here, but unfortunately not. As a developer, if I’m going to be working with a client or a product team via a prompt manager I would expect more proactive error detection and clearer communication of issues so that I can be relatively confident that the prompt team is making obvious error when they update prompts.
This teardown was conducted with respect for Langfuse’s team and product, I hope this was useful to them, and I welcome any feedback or updates to the post.