
How do you measure prompts?

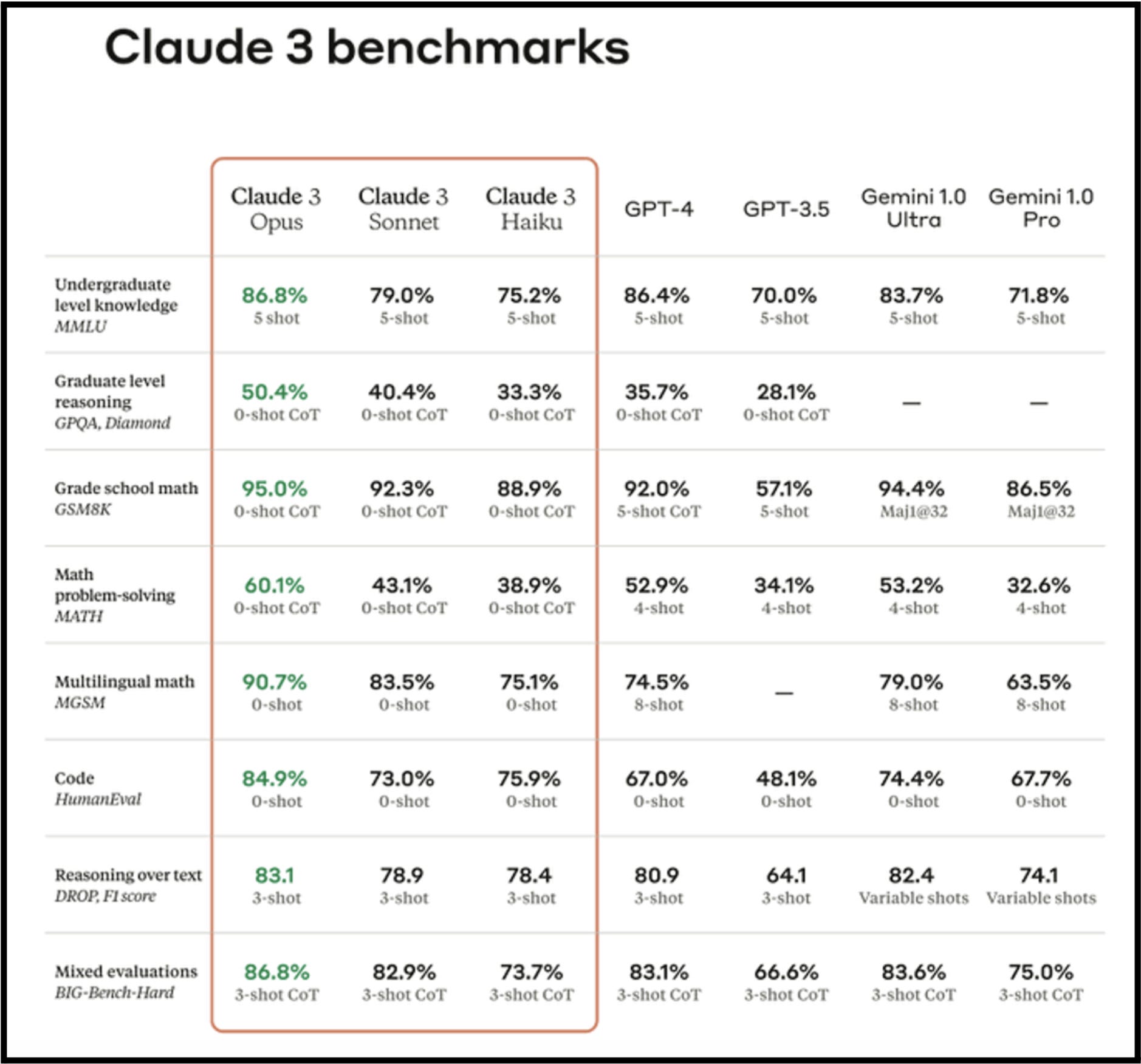
Whenever a new model comes out you see an image like this one with a set of benchmarks. I have no idea what these benchmarks actually mean. Every time you run a prompt the results are different so how can you compare responses. I would like to better understand the nuance around how they create tests reliable enough to standardize performance.
More than understanding how to evaluate LLM responses, I interested to know if you can measure and score the performance of a prompt. If I’m building an AI app, I can only influence the quality of my prompts. If there are benchmarks then there is a way to measure response quality, and therefore there must be a way to quantify teh quality of a prompt. If you can quantify prompts then a prompt manager could theoretically audit your prompts, and track improvements over time.