
Evaluating LLM-based Applications

Yesterday’s post posed a question around how you measure prompts? If you are building an AI powered application how do you know if you’re app is production ready or if it just works on a handful of examples you’ve tested it on.
Today I found Josh Tobin’s 2023 talk at Databricks that thoroughly answered this question.
I recommend watching the whole video if you have the time. If you don’t, then here is my best attempt to summarize what I’ve learned.
At a high level, there are four main ways that people building AI-powered products can evaluate their prompts, each with it’s own tradeoffs.
Public benchmarks - Great for comparing LLM models to each other but not so great at determining whether a new model is at good at the specific task your product accomplishes.
User testing - Which is when you see how your users interact with a small number of inputs.
AutoEval - This involves getting an LLM to evaluate your app’s AI responses.
Rigorous Human evaluation - Which is great, but slow and expensive and not always immune to human bias and inconsistencies.
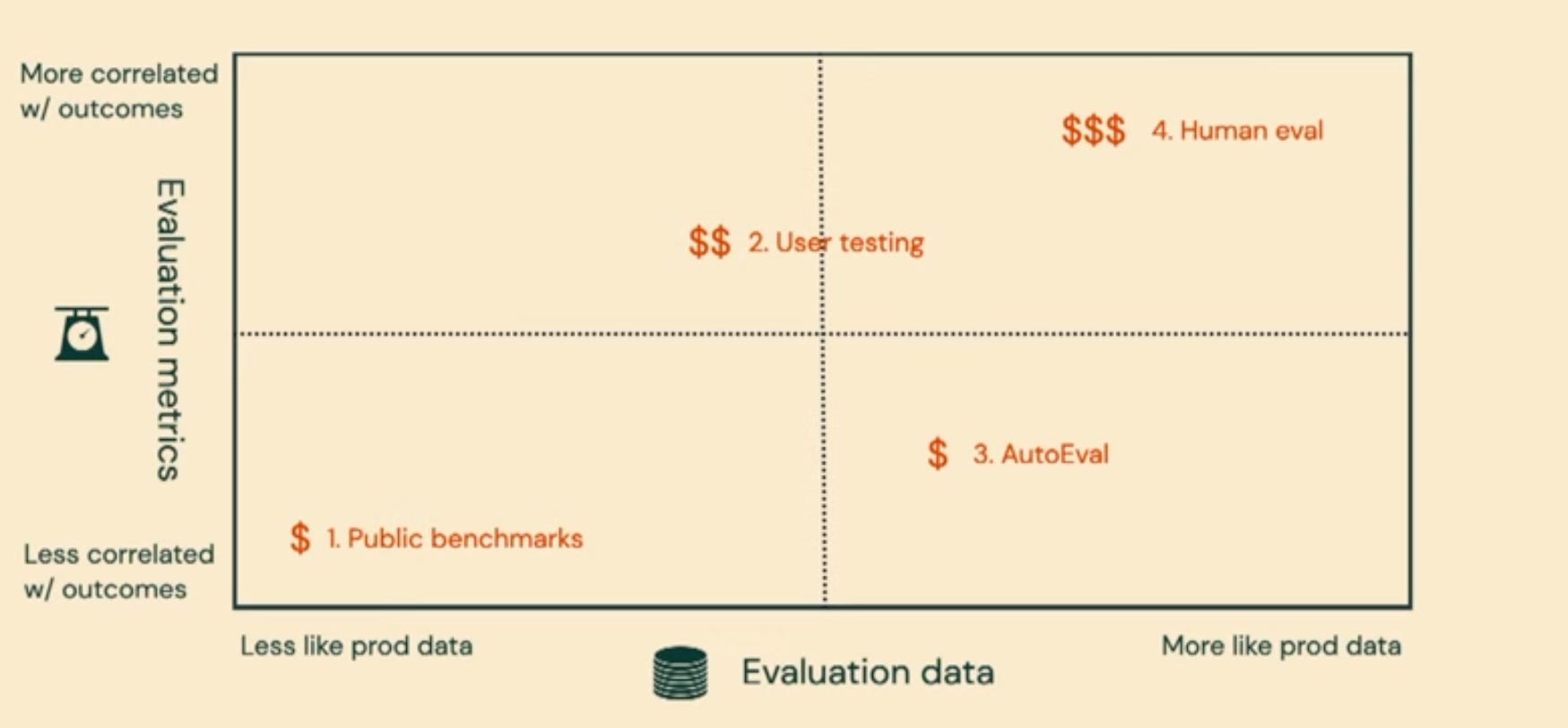
Each approach is based on a decision about the metrics (y-axis) and data (x-axis) you are going to use for your evaluation.
A “good” metric is one that is highly correlated to the thing your app helps people do. Public benchmarks can tell you how good a model is at correctly answering a question from a block of text (for example, being able to tell you what colour was the rabbit’s house in a 10,000 word story) but this could be a terrible metric if it has nothing to do with what your app does (making LinkedIn ads in my case).
Good data, on the other hand, is data that resembles the kinds of inputs you would get from users in a real world scenario. Evaluating my app with on a bunch of data about building LinkedIn ads for storybooks about rabbits would be an example of poor data. Not many people promote children’s books on LinkedIn.
Josh’s conclusion is that if you are serious about building applications on-top of LLMs then you need to build your own evaluation set for he tasks that you care about. You iteratively build a test data set out and use an LLM to evaluate changes in a fast feedback loop. Once you have a set of changes you are reasonably confident with you can pass them off to a slower, but more rigorous human evaluation process for approval. Once deployed you roll the changes out slowly and collect user feedback (in the form of votes, annotations, error reports, etc) at each level of rollout and use this to further improve your evaluation data set.
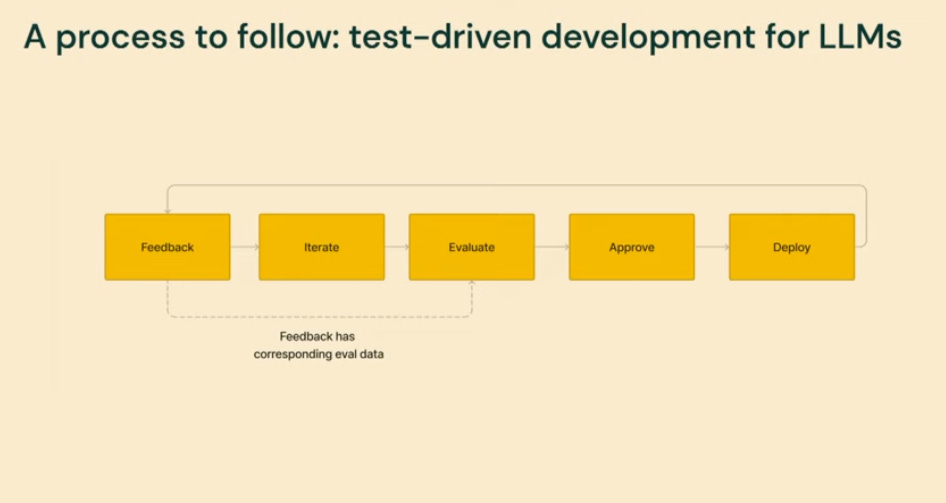
The way to do build out the initial evaluation set is to:
Start with an ad-hoc data set. A bunch of test inputs to see if your app is producing the kinds of outputs you expect. If there is a “correct” answer to the type of question you’re asking then scoring the responses should be fairly straight forward. If not then you go for the next best thing and compare responses against reference answer, and/or previous answers, and/or human feedback (up/down votes on responses).
As you find interesting examples you save them to a test set. An interesting example could be one that is surprisingly hard for the product to get right, or one that yield a very different response to the one you’d expect.
Then use an LLM to generate more examples for your test set. Either to pad out underrepresented topic, or to build out variations for different formats and tones, etc.
Then you roll the application out to a small group of trusted friends and collect feedback on responses they liked and disliked and why. Use this to improve your data set and then progressively roll the app out to your broader team, your compliance team, your legal department, a subset of your users, then your Alpha users and then eventually to all of your users, collecting feedback and iterating and each stage.
To summarise: Start incrementally. Leverage LLMs. Incorporate user feedback.
The big takeaway for me from this talk was that there really is no definitive way to evaluate a product built on an LLM. There are only shades of gray. You have make a bunch of tradeoff in terms of the metrics you pick and the data you use. Even with Josh’s human-verified LLM eval approach you are still subject to bias from the LLM evaluation and bias from the final human verification.
I guess the next step for me is to see how all of this plays out in practice. I think it sound great in theory but I need to actually create an evaluation set for my LinkedIn app and see how it all comes together.